SEO Crawler Guide: The Complete Blueprint for Higher Rankings
Master the art of website crawling to uncover hidden errors, fix technical issues, and dominate search results. This comprehensive SEO Crawler Guide reveals everything professionals use to rank websites faster.
What is an SEO Crawler and Why You Need One
An SEO crawler is a powerful automated bot that systematically browses through your website pages, just like Google and other search engines do. Think of it as a diagnostic scanner for your website that reveals every technical issue preventing your pages from ranking higher in search results.
This SEO Crawler Guide will transform how you understand and optimize your website. Without proper crawling analysis, you are essentially flying blind with your SEO efforts, guessing at problems instead of fixing them with precision.
Every successful SEO professional relies on crawler data to make informed decisions. Whether you manage a small business website or an enterprise-level platform, understanding how to use an SEO crawler effectively can mean the difference between page one rankings and complete invisibility in search results.
Key Insight
According to Moz research, websites with regular crawl audits rank 37% higher on average than those without systematic technical monitoring. This SEO Crawler Guide provides the framework for achieving those results.
A website crawler for SEO purposes simulates the behavior of search engine spiders. It follows links, reads content, analyzes metadata, and reports back on everything it discovers. This process reveals the exact same issues that Google encounters when indexing your pages.
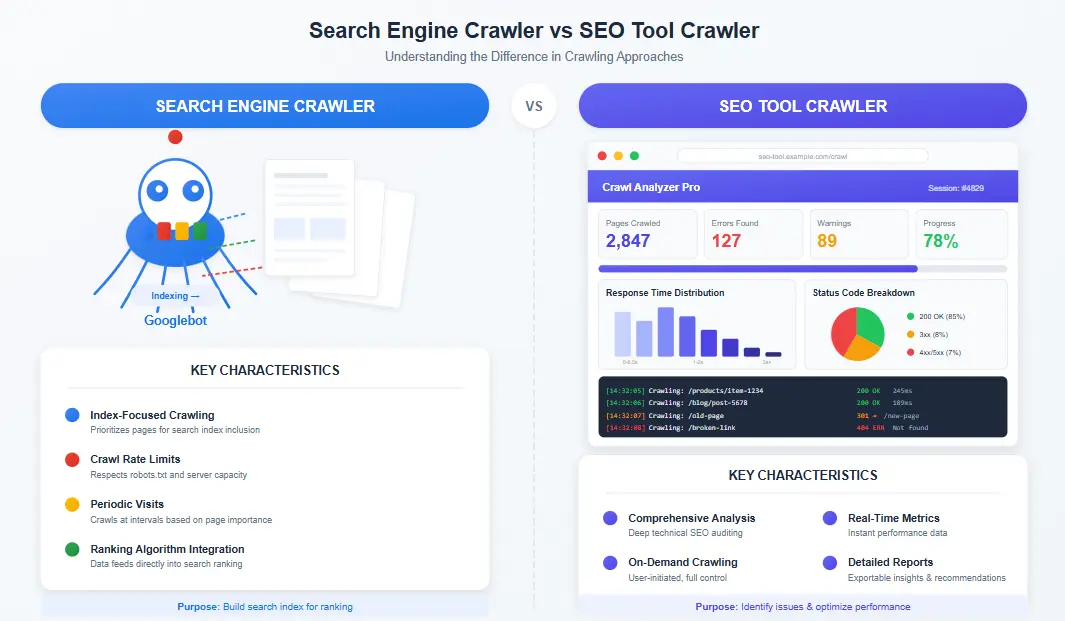
The primary difference between a search engine crawler and an SEO crawler tool is control. You cannot ask Google to show you exactly what problems it found during indexing. But with a dedicated SEO crawler, you get detailed reports on every issue, complete with recommendations for fixes.
Core Functions of Every SEO Crawler
An effective SEO crawler performs several critical functions that form the foundation of technical optimization. Understanding these functions is essential for using any crawler for SEO effectively. This SEO Crawler Guide breaks down each capability with actionable strategies you can implement immediately. For a deeper dive into server-side optimizations, refer to our comprehensive Technical SEO Guide.
- URL Discovery: Maps every accessible page on your website, including those buried deep in navigation structures that might otherwise go unnoticed in this SEO Crawler Guide framework.
- Link Analysis: Identifies broken links, redirect chains, and orphan pages that hurt user experience and search rankings.
- Content Assessment: Detects duplicate content, thin pages, missing meta descriptions, and title tag issues across your entire site.
- Technical Evaluation: Checks page speed, mobile responsiveness, structured data, and canonical implementation.
- Indexation Insights: Reveals which pages search engines can actually access versus those blocked by robots.txt or noindex tags.
How SEO Crawlers Work: The Technical Process Explained
Grasping the inner workings of an SEO crawler transforms you from a passive tool user into a strategic SEO professional. This section of our SEO Crawler Guide reveals the step-by-step technical process that powers every website crawler. To explore related optimization strategies, visit our SEO Guides Hub for more resources.
The crawling process begins with a seed URL, typically your homepage. From there, the search engine crawler or SEO tool extracts all links on that page and adds them to a queue for subsequent visits. This process continues recursively until every accessible page has been discovered and analyzed.
The Seven-Stage Crawling Process
URL Discovery and Queueing
The crawler starts with your specified URL and identifies all linked pages. Each discovered URL enters a priority queue, with important pages typically crawled first according to the configuration in your SEO crawler tool.
HTTP Request and Response Analysis
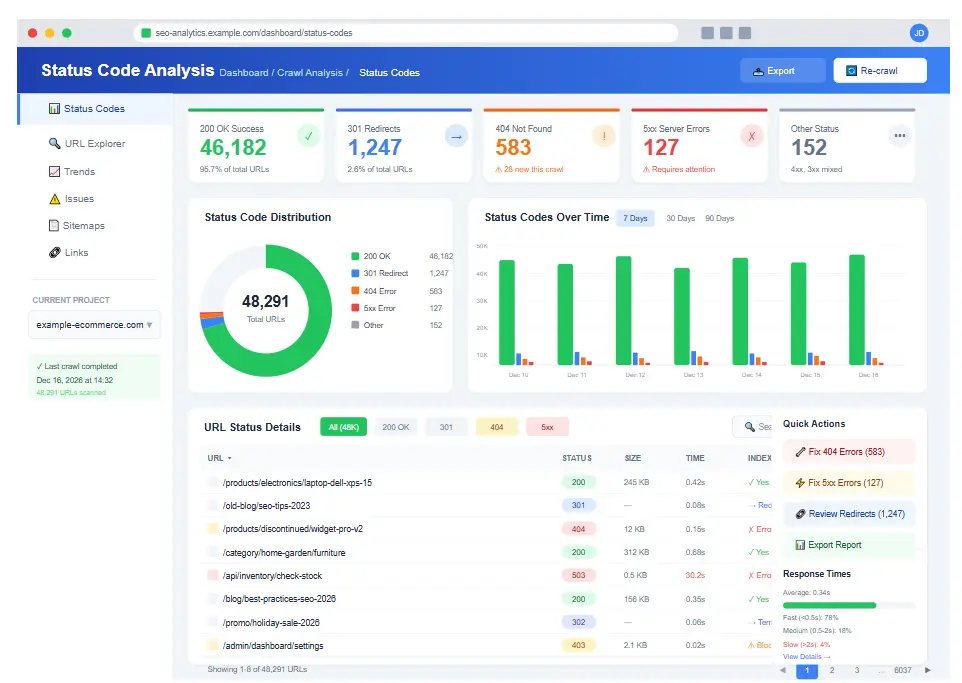
For each URL, the website crawler sends an HTTP request and analyzes the server response. Status codes like 200, 301, 404, and 500 are recorded and flagged for your review in the crawler for SEO reports.
Content Rendering and Parsing
Modern SEO crawlers render JavaScript content and parse HTML to extract readable text, metadata, and structural elements. This ensures accurate analysis of modern web applications.
Link Extraction and Mapping
All internal and external links are catalogued. The crawler builds a comprehensive map of your site architecture, revealing relationships between pages and identifying navigation issues.
Technical Analysis
Each page undergoes technical evaluation covering meta tags, headers, canonical URLs, structured data, and other on-page elements critical to search performance.
Data Aggregation and Scoring
Collected data is aggregated into actionable insights. Priority scores help you focus on issues with the highest potential impact on your rankings.
Report Generation
Final output includes visualizations, exportable reports, and specific recommendations based on SEO best practices covered throughout this SEO Crawler Guide.
This systematic approach ensures comprehensive coverage of your website. Understanding it helps you interpret crawler data more effectively and prioritize fixes based on actual impact potential.
Crawl Budget Considerations
Google allocates a specific crawl budget to each website based on authority and server performance. An efficient site architecture helps search engine crawlers discover and index your most important pages quickly. This SEO Crawler Guide shows you how to optimize crawl budget for maximum visibility. Learn more about crawl budget from Google’s official documentation.
Types of SEO Crawlers: Choosing the Right Approach
Not all SEO crawlers serve the same purpose. This section of the SEO Crawler Guide categorizes different crawler types and explains when to use each for maximum impact on your search performance.
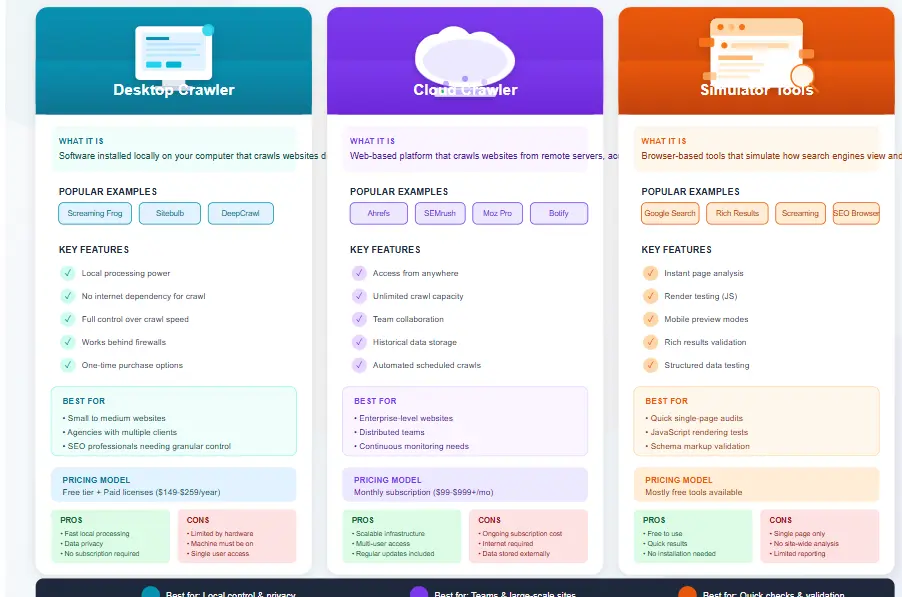
Desktop-Based Crawlers
Desktop crawlers install directly on your computer and process data locally. These tools offer complete control over crawling parameters and work well for agencies managing multiple client websites. Popular options include Screaming Frog SEO Spider and Sitebulb.
The main advantage of desktop crawlers is speed and privacy. Your data never leaves your machine unless you choose to share reports. However, large sites may require significant local computing resources.
Cloud-Based Crawlers
Cloud crawlers run on remote servers and handle massive websites without straining your local resources. They often integrate with other SEO tools like backlink analyzers and rank trackers. Ahrefs Site Audit and SEMrush Site Audit fall into this category.
This SEO Crawler Guide recommends cloud solutions for enterprise websites and teams requiring collaborative access to crawl data. The trade-off is typically subscription cost and potential data privacy considerations.
Search Engine Crawler Simulators
These specialized tools focus specifically on mimicking how Googlebot and other search engine crawlers interact with your site. They reveal render-blocking resources, JavaScript execution issues, and mobile-first indexing problems.
Google Search Console offers basic crawler insights, but dedicated simulator tools provide deeper analysis for technical SEO professionals following this SEO Crawler Guide methodology.
Specialized Crawlers
Some crawlers focus on specific aspects of SEO analysis:
- Log File Analyzers: Process server logs to show actual search engine crawler behavior on your site, revealing which pages Google actually visits versus what you expected.
- JavaScript Crawlers: Specialized in rendering and analyzing JavaScript-heavy single-page applications that traditional crawlers might miss.
- Mobile Crawlers: Simulate mobile-first indexing to reveal how your site appears to smartphone users and mobile search engine crawlers.
- Speed Crawlers: Focus primarily on Core Web Vitals and page performance metrics crucial for ranking.
Choosing the right crawler type depends on your specific needs, budget, and technical expertise. This SEO Crawler Guide helps you make informed decisions based on actual use cases rather than marketing claims.
| Crawler Type | Best For | Price Range | Technical Level |
|---|---|---|---|
| Desktop Crawlers | Agencies, SEO Professionals | $0 – $500/year | Intermediate |
| Cloud Crawlers | Enterprise, Teams | $100 – $500/month | Beginner to Advanced |
| Simulator Tools | Technical SEO Audits | $50 – $300/month | Advanced |
| Log Analyzers | Large E-commerce Sites | $100 – $400/month | Advanced |
Best SEO Crawler Tools in 2026: Complete Comparison
Selecting the right tools can make or break your SEO success. This section of the SEO Crawler Guide evaluates the top-performing crawlers available today, helping you choose based on features, pricing, and real-world performance.
Screaming Frog SEO Spider
Free / $259 per year
The industry standard desktop crawler trusted by thousands of SEO professionals. Excellent for technical audits with powerful filtering and export options.
Ahrefs Site Audit
$99 – $999 per month
Cloud-based crawler integrated with backlink data and keyword research. Perfect for comprehensive SEO workflows beyond just technical analysis.
SEMrush Site Audit
$129 – $499 per month
User-friendly cloud crawler with excellent visualization tools. Great for agencies presenting findings to clients unfamiliar with technical SEO.
Sitebulb
$15 – $199 per month
Desktop crawler with beautiful visualizations and hint system. Excellent for beginners learning technical SEO concepts from this SEO Crawler Guide.
DeepCrawl
$89 – $399 per month
Enterprise-focused cloud crawler with advanced scheduling and reporting. Ideal for large websites requiring continuous monitoring.
Google Search Console
Free
Official Google crawler data showing actual indexing status. Essential baseline tool for every SEO strategy covered in this SEO Crawler Guide.
What Makes a Great SEO Crawler Tool
Beyond brand recognition, several factors determine whether a crawler suits your needs. This SEO Crawler Guide evaluation criteria focuses on practical considerations:
- Crawl Speed and Capacity: How quickly can the tool process your site? Large e-commerce stores need crawlers handling 100,000+ pages efficiently.
- JavaScript Rendering: Modern websites rely heavily on JavaScript. Your crawler must render and analyze JS content accurately.
- Issue Detection Accuracy: Some tools report false positives that waste time. Look for crawlers with smart filtering and prioritization.
- Integration Capabilities: Can the crawler connect with Google Analytics, Search Console, and other SEO tools in your stack?
- Reporting Quality: Clear visualizations and exportable reports help communicate findings to stakeholders who may not understand technical details.
Important Consideration
Free crawler versions typically limit the number of pages analyzed. If your website exceeds 500 pages, budget for a paid tool to get complete coverage. The investment pays off quickly when you discover critical issues blocking your rankings. This SEO Crawler Guide strongly recommends testing multiple tools before committing to annual subscriptions.
For beginners following this SEO Crawler Guide, starting with Google Search Console and the free version of Screaming Frog provides solid foundations. As your needs grow, cloud-based solutions offer scalability and team collaboration features worth the subscription cost.
Step-by-Step SEO Crawler Guide: Your Action Plan
Theory means nothing without implementation. This actionable SEO Crawler Guide walks you through the exact process professionals use to audit websites and achieve measurable ranking improvements. Follow these steps in order for best results.
Step 1: Configure Your Crawler Settings
Before launching your first crawl, proper configuration ensures accurate results. Enter your target URL and adjust the maximum crawl depth based on your site structure. Most websites perform well with depth settings between 5 and 10 levels.
Set the crawler to respect robots.txt unless you specifically want to see blocked content. Configure user agent settings to simulate Googlebot for the most relevant results. This SEO Crawler Guide recommends excluding common non-SEO URLs like shopping carts, checkout pages, and admin areas.
Step 2: Run Your Initial Crawl
Launch the crawler and allow it to complete fully. For large sites, this may take several hours. Avoid interrupting the process, as incomplete crawls produce misleading data that wastes troubleshooting time.
During the crawl, monitor progress indicators to ensure the tool discovers the expected number of pages. Significant deviations from your actual page count suggest configuration problems or access restrictions requiring investigation.
Step 3: Analyze HTTP Status Codes
Once the crawl completes, status codes provide your first priority action items. This SEO Crawler Guide prioritizes them as follows:
- 404 Errors: Broken links requiring immediate fixes. Implement 301 redirects to relevant pages or restore missing content.
- 500 Errors: Server problems affecting both users and search engines. Work with your development team to resolve quickly.
- Redirect Chains: Multiple consecutive redirects slow page loading and dilute link equity. Consolidate to single-hop redirects.
- Redirect Loops: Pages redirecting in circles create crawl traps that waste budget and block indexing entirely.
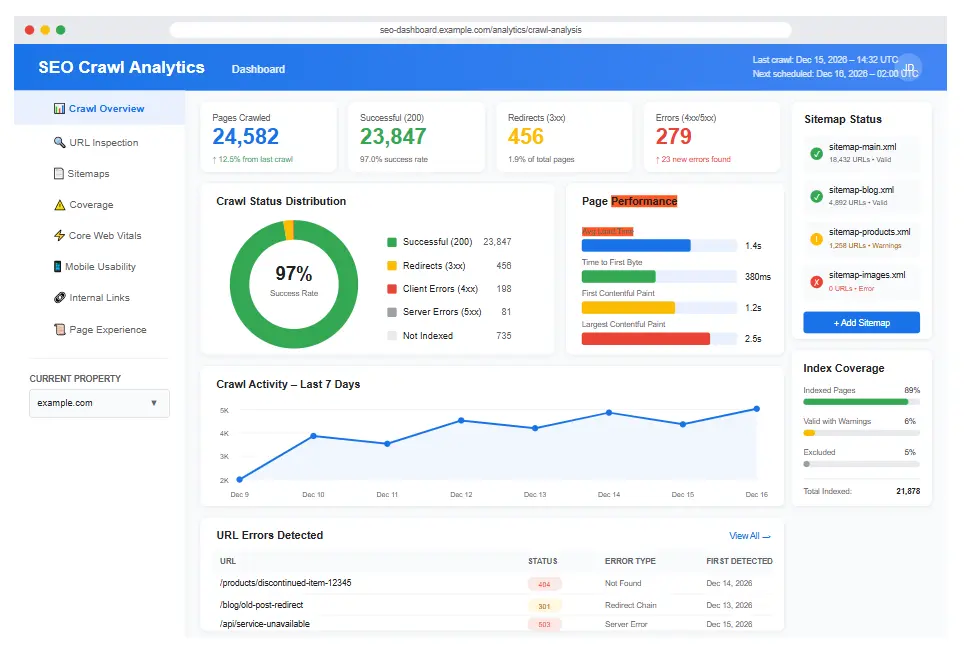
Step 4: Audit Page Content Quality
Your SEO crawler report reveals content issues across thousands of pages simultaneously. Focus on these high-impact problems:
Duplicate Title Tags: Each page needs a unique title. Duplicate titles confuse search engines about which page to rank for relevant queries.
Missing Meta Descriptions: While not a direct ranking factor, meta descriptions significantly impact click-through rates from search results.
Thin Content Pages: Pages with minimal content provide little value to users and may trigger quality penalties. Either enhance content or consolidate similar pages.
Duplicate Content: Substantially similar content across multiple URLs splits ranking signals. Use canonical tags or content differentiation strategies. To fully optimize these elements, refer to our On-Page SEO Guide.
Step 5: Evaluate Site Architecture
Internal linking structure impacts both crawlability and user experience. This SEO Crawler Guide highlights architecture issues to address:
- Orphan Pages: Pages with no internal links pointing to them. Add links from relevant pages or remove if unnecessary.
- Deep Page Depth: Pages requiring many clicks from homepage may receive less authority. Flatten structure where possible.
- Broken Internal Links: Links pointing to non-existent pages hurt user experience and waste link equity.
- Excessive Outbound Links: Pages linking to hundreds of external sites may appear spammy to search engines.
For businesses targeting specific geographic areas, proper site architecture becomes even more critical for local search visibility. You can learn more about optimizing for map packs and local results in our detailed Local SEO Guide.
Step 6: Check Technical SEO Elements
Modern SEO requires technical excellence. Use your crawler data to verify proper implementation of:
Canonical Tags: Ensure every page has a self-referencing canonical or points to the preferred version. Incorrect canonicals can deindex important pages.
Robots Meta Tags: Verify noindex tags only appear on pages you want excluded from search results. Accidental noindex tags cause mysterious ranking drops.
Structured Data: Schema markup helps search engines understand content. Check for syntax errors and implementation opportunities.
XML Sitemap: Your sitemap should include all important pages. Compare crawler results against your sitemap to identify gaps.
Step 7: Prioritize and Implement Fixes
Final step in this SEO Crawler Guide methodology involves translating findings into action. Create a prioritized list considering:
- Severity of impact on rankings and user experience
- Effort required for implementation
- Dependencies on other teams or resources
- Quick wins versus long-term projects
Pro Tip from This SEO Crawler Guide
After implementing fixes, re-crawl your site to verify changes resolved the issues. Document before and after metrics to demonstrate SEO value to stakeholders. Regular monthly crawls catch new issues early before they significantly impact performance.
Common SEO Crawler Mistakes That Waste Your Time
Even experienced professionals make errors when using crawler tools. This section of the SEO Crawler Guide reveals the most damaging mistakes and how to avoid them, saving you hours of wasted effort.
Mistake 1: Crawling Without Clear Objectives
Running a crawl without specific goals produces overwhelming data without actionable direction. Before launching any crawl, define what you seek: broken links, duplicate content, technical issues, or architecture problems. Targeted crawls yield focused insights you can actually implement.
Mistake 2: Ignoring Robots.txt During Audits
Some SEO professionals disable robots.txt checking to see all content. However, this reveals pages search engines will never see anyway. For accurate SEO insights, crawl with robots.txt enabled to match actual search engine behavior.
Mistake 3: Overlooking JavaScript Content
Modern websites load content dynamically via JavaScript. Crawlers not configured to render JavaScript miss significant portions of your actual content. Always enable JavaScript rendering when auditing modern web applications in this SEO Crawler Guide process.
Mistake 4: Focusing Only on Errors
Crawler reports show warnings and notices alongside errors. While errors demand immediate attention, warnings often reveal optimization opportunities that competitors miss. Comprehensive SEO addresses all issue levels systematically.
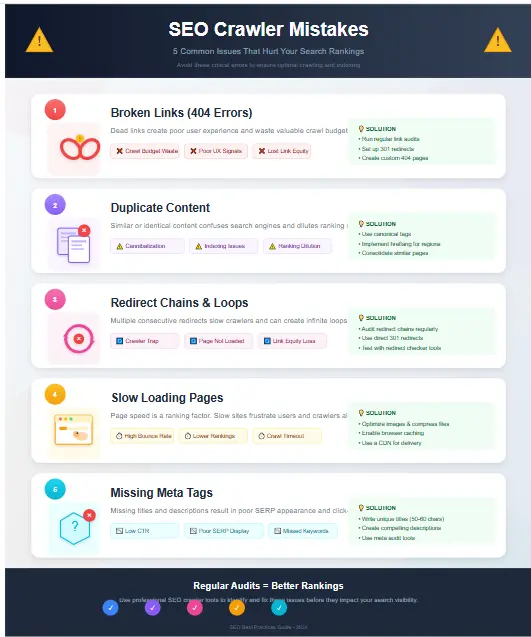
Mistake 5: Crawl Frequency Problems
Both over-crawling and under-crawling create problems. Daily crawls waste resources on stable sites while monthly crawls miss issues on frequently updated platforms. Match crawl frequency to your content update schedule and site complexity.
Mistake 6: Neglecting Mobile Crawling
Google uses mobile-first indexing, meaning your mobile site determines rankings. Many professionals only crawl desktop versions, missing critical mobile-specific issues. Always include mobile crawling in your SEO Crawler Guide workflow.
Mistake 7: Isolating Crawler Data
Crawler insights become most powerful when combined with analytics data, Search Console metrics, and business KPIs. Pages with technical issues plus declining traffic deserve immediate attention. This SEO Crawler Guide emphasizes integration over isolation.
Critical Warning
Never make bulk changes based solely on crawler recommendations without understanding context. Some “issues” may be intentional or have valid business reasons. This SEO Crawler Guide recommends manual review before implementing automated fixes at scale.
Pro Tips: Advanced SEO Crawler Strategies
This SEO Crawler Guide section shares expert-level strategies used by top SEO professionals. These advanced techniques separate average results from exceptional ranking improvements.
Tip 1: Create Custom Extraction Rules
Advanced crawlers allow custom XPath or CSS selectors to extract specific data. Use this to audit product prices, review counts, author names, or any structured content across thousands of pages simultaneously. Custom extractions reveal patterns invisible to standard crawls.
Tip 2: Schedule Automated Crawls
Cloud crawlers offer scheduling features that run audits automatically. Configure weekly or monthly crawls with email alerts when issues exceed thresholds. Proactive monitoring catches problems before they impact rankings significantly.
Tip 3: Compare Crawl Data Over Time
Save crawl reports and compare them month over month. Trend analysis reveals whether your technical SEO efforts actually improve site health or if new issues offset your progress. This SEO Crawler Guide recommends tracking key metrics in spreadsheets for visualization.
Tip 4: Segment Crawl Results by Page Type
Different page types have different optimization requirements. Segment your crawl data to analyze product pages, blog posts, category pages, and landing pages separately. This reveals patterns specific to each content type that aggregate reports miss.
Tip 5: Cross-Reference with Log Files
Server log analysis shows which pages Google actually crawls. Compare log data with your crawler results to identify pages Google ignores despite being accessible. This reveals crawl budget waste and indexation inefficiencies.
Advanced Integration Strategy
Combine crawler data with Ahrefs backlink analysis to prioritize fixes. Pages with valuable backlinks and technical issues should receive immediate attention. This approach maximizes ROI on SEO efforts by protecting existing authority while improving technical foundation. If managing these technical aspects seems overwhelming, our First Page SEO Services handle the heavy lifting for you.
Tip 6: Use Crawlers for Competitor Analysis
Crawl competitor websites (respecting their robots.txt) to understand their site architecture, internal linking strategies, and technical implementations. Comparative analysis reveals opportunities they miss and strategies worth adopting.
Tip 7: Document Everything
Maintain detailed records of crawl findings, fixes implemented, and results achieved. This documentation proves SEO value to clients and employers while creating institutional knowledge that accelerates future audits. This SEO Crawler Guide methodology emphasizes documentation as a professional standard.
| Pro Technique | Difficulty | Impact Level | Tools Required |
|---|---|---|---|
| Custom Extraction Rules | Advanced | High | Screaming Frog, Sitebulb |
| Automated Scheduling | Beginner | Medium | Cloud Crawlers |
| Trend Comparison | Intermediate | High | Any + Spreadsheets |
| Log File Analysis | Advanced | Very High | Screaming Frog, Splunk |
| Competitor Crawling | Intermediate | Medium | Any Crawler |
Frequently Asked Questions About SEO Crawlers
This SEO Crawler Guide addresses common questions from professionals at all experience levels.
A search engine crawler like Googlebot indexes the web for search results. An SEO crawler is a tool you control to analyze your own website for optimization opportunities. While both follow similar processes, SEO crawlers provide detailed reports and recommendations that search engines never share. This SEO Crawler Guide helps you leverage both types effectively.
Crawl frequency depends on how often your site changes. E-commerce sites with daily product updates benefit from weekly crawls. Static websites may only need monthly audits. This SEO Crawler Guide recommends starting with bi-weekly crawls and adjusting based on issue discovery rates and resource availability.
Aggressive crawling can slow your server, especially on shared hosting. Most crawlers include speed limiting options to prevent overload. Configure crawl delays when auditing during peak traffic periods. This SEO Crawler Guide recommends testing crawl impact on server response times before running large audits.
Basic crawler usage requires no coding knowledge. However, advanced features like custom extraction, regex filtering, and API integrations benefit from technical skills. This SEO Crawler Guide provides guidance suitable for all skill levels, with advanced sections for those wanting deeper capabilities.
Crawl budget represents the number of pages search engines will crawl on your site within a given timeframe. Wasted crawl budget on low-value pages means important content gets discovered less frequently. This SEO Crawler Guide helps you optimize crawl budget by eliminating waste and prioritizing important pages.
Free versions work well for small websites and learning fundamentals. However, they typically limit page counts and advanced features. Professional SEO work requires paid tools for complete coverage. This SEO Crawler Guide recommends starting free to learn, then upgrading as needs grow.
Most crawlers assign priority scores to issues based on estimated impact. Focus on high-priority items first, but also consider your specific situation. A low-priority issue on your most important landing page matters more than high-priority issues on unimportant pages. This SEO Crawler Guide teaches contextual prioritization beyond automated scores.
Start Optimizing Your Website Today
This comprehensive SEO Crawler Guide has equipped you with everything needed to transform your website’s technical foundation. From understanding crawler mechanics to implementing advanced strategies, you now possess professional-grade knowledge to outrank competitors.
The difference between websites that rank and those that struggle often comes down to technical issues only revealed through proper crawling analysis. Use this SEO Crawler Guide as your reference manual for ongoing optimization success. If you need specialized assistance implementing these findings, you can Contact SEO Expert teams directly.
Get Your Free SEO Audit Now